
AI Platforms, Markets, & Open Source
What does the future market structure look like for AI foundation and API companies? How does OSS play a role in a world of ever scaling models?

(I originally wrote this post a few months ago and sat on it. Since then Google has announced entering the market and MSFT announced Bing and other AI integrations. So updating and publishing now and will undoubtedly be wrong again in a few months).
The AI world is divisible into roughly 3 areas (this is a massive oversimplification of course):
1. Large language models. These are general purpose models like GPT-4 or Chinchilla in which the web (or other source of text / language) are ingested and transformed into models that can do everything from summarize legal documents to be used a search engine or friendly chat bot.
2. Image generation which includes models like Midjourney, Dall-E, or Stable Diffusion as well as currently simple video approaches and 3D models like NeRF. These models allow you to type a prompt to generate an image.
3. Other (really a very large set of other tech & markets that really should *not* be naturally clustered together). This includes robotics, self driving cars, protein folding, and numerous other application areas. I am dramatically over simplifying things in a dumb way by bucketing lots of stuff here. Obviously different model architectures and end markets exist for AlphaFold 2 versus self driving cars. However, this is meant to be a short post versus a book, so please bear with me. For this post I am going to ignore everything in this bucket for now.
When people talk about “Generative AI”, they tend to mix these areas together into one big bucket. In reality, each of these markets have different underlying AI model architectures, compute and scaling needs, quality bars, and application areas. It is important to segment them out to try to infer what futures they might bring.
A. Image generation versus LLMs: very different costs, quality, scale, segments

Image generation will likely transform multiple areas including:
Social products and images (see e.g. future versions of Lensa like products, or their integration into core social platforms)
Graphic and visual design
Movies, comics, anime, manga
Video games
CAD
Architecture
Aspects of ecommerce
Etc etc lots to do
Performant video (and voice), of course, opens up additional application areas.
The range of societally transformative applications for images, while large, may be much smaller than the total surface area for text and language in the very near term. This of course may change over time via video, voice, and other interfaces in the future. Right now most B2B applications are language-centric (text and then to a lesser degree voice), while consumer is mixed (social like Twitter, Facebook, TikTok, YouTube, ecommerce like Amazon, Airbnb, etc).
While Image generation opportunities listed above are all large areas, they are dwarfed by the potential applications of language if you look at corresponding company market cap and revenue. Language is a core part of all B2B interactions, social products, commerce and others areas. LLMs are likely up to a few orders of magnitude more important than image gen in the very near term on an economic basis, and image gen is incredibly important to begin with.
A.1 Image gen is cheap to model compared to LLMs
In general, image generation models that have seen massive success can be trained on reasonably small amounts of dollar and compute. For example, the latest version of Stable Diffusion was likely trained on, at most, a few hundred thousands to a few million dollars of GPU time.
A.2 Image gen quality: swapping pixels is not the same as swapping words
In general, image generation has more subjective quality bar than language. Beauty truly is in the eye of the beholder and even an imperfect image can provide useful output. Swapping two pixels may not impact the value of an image much, while swapping two words can dramatically change the meaning of a paragraph.
A.3 Image gen potential market structures
Image generation models seem easier to predict a higher probability path for - most likely we will see a mix of proprietary closed source models (the “Disney Model” for making Disney images) and open source models (Stable Diffusion et al) alongside general purpose closed source tools (Midjourney, Dall-E) and area specific closed source models (“Graphic Design AI startup co”). These models will likely be reasonably cheap to train (hundreds of thousands to tens of millions) and largely differentiated by IP or specific use case (e.g. “Marvel Comics data set” versus “specialized photo design tool”). A reasonable subset of these models will also be able to run locally on phones or other devices versus just in the cloud - further opening up application areas.
Image gen may ultimately differentiate based on proprietary data sets and training approaches versus raw scale of capital/compute and data in the short term. Most image gen approaches are based on diffusion models, with some people exploring the transition to transformers or hybrids. Other models may also impact the approaches or economics of these models and therefore the evolution of the industry. However, in the short term there is less uncertainty on the like world of image generation in the next few years. Open source is likely to continue to play a key role in the evolution of products in this area over time.
This means the bigger area of uncertainty is - what is the likely path for LLMs?
B. LLMs and foundation models
Language includes applications like:
Search
Most B2B interactions, sales, ERP, document use and management, email, etc
Code, data interactions, code gen, SQL, excel, etc.
Finance
Most social and consumer products
Chat, texting, and other applications
“Co-pilot for everything” - all white color jobs (legal, accounting, medicine, etc)
There are open questions on which of these areas require large language models versus smaller niche ones. To date, the LLMs seem to outperform niche models in some, but not all areas.
There are a few likely paths for large language models, and potential end market structure. Market structures matter a lot as it determines both the economic and talent winner in an ecosystem (who gets all the revenue, talent, profits, market cap and innovation).
B1: Potential LLM market structures
Potential paths include:
1. “TSMC world” - one at scale winner (decreasing probability over time)
TSMC is the world’s biggest outsourced fab. It has nailed process engineering and scale, and used the most advanced semiconductor equipment in the world. Its market cap is much larger than any other fab, and it has highly specialized expertise in house to enforce this.
In the TSMC analogy, given the current active market players, OpenAI currently has a lead on being the sole winner. Its current pole position is reinforced via scale and capitalization via the Microsoft (or others) partnership and its apparent increasingly velocity in aggregating data, talent, know how, and compute.
Google is the next most likely candidate to be the sole winner in this world if its new product offerings manage to subsume OpenAI. Google seems to be awakening to the competitive threat of OpenAI and others. Other startups like Anthropic, Character, or startups trying to build AGI, could always provide a wild care to the end winner in the future of AI.
“TSMC world” is roughly a monopoly market with a sole provider being dominant. This seems decreasingly likely as competition heats up in this market.
2. Cloud service provider world - oligopoly market (most likely world)
The cloud wars ended up with AWS, Azure, and GCP as three large scale, fierce competitors. This is an oligopoly market with no single winner. Based on what we currently know about the world, this seems the most likely near term market structure for foundation language models, but it is early days and the future is uncertain.
An oligopoly market for LLMs would be if OpenAI, Google, and 1-2 other companies all ended up with strong market share split between them in the AI API and services world. Many of the customers I spoke with who use LLM platforms want a second source model to OpenAI, if only to have more bargaining power or to experience more data privacy, suggesting room for another competitor. For example, one could argue the reason Juniper exists is so enterprises can second source Cisco.
The reason to argue for a near term oligopoly market, versus likely fragmentation, is due to the capital/compute/data scale costs currently needed for each subsequently better performing LLM model. If GPT-3 at the time cost a few million to ten million or so to train, and GPT-4 from scratch may be estimated at tens of millions to maybe a hundred million, maybe GPT-5 is a few hundred million and GPT-N is a billion. This of course assumes that costs will scale faster than technical breakthroughs or drops in GPU (or specialized hardware cost declines) and these may be false assumptions.
However, in general “scale” has proven to be important for many deep learning approaches with algorithmic approaches often then reapplied at scale.
If the ongoing scaling of capital needs continues for ever larger models, a few implications drop out:
1. For some period of time, a strong moat will exist for foundation model companies, limiting new entrants (or forcing every startup to have a “strategic” backer with deep financial pockets). For example if it eventually costs $500M+ to train each new model generation, not many companies will be able to afford to compete[1].
2. The eventual capabilities of a foundation model on a single architecture should in the limit approach an asymptote, eventually removing the competitive advantage or big step function with each model/scale. This may take some time and is in the extreme a race of asymptote versus AGI, as well as further technological breakthroughs that could accelerate progress indefinitely. Moore’s “law”, which was more an observation than an actual law, lasted longer than anyone originally expected.
3. Older versions of models may be cheaper to retrain equivalents of, meaning fragmentation and/or open sources will be a generation behind. For example, imagine it costs $1B to train GPT N and maybe it is 1/10th the price for GPT N-1 and 1/100th the price for GPT N-2 equivalents. Thus any applications using earlier versions of models will no longer need to live on the main platform APIs and can revert to open source or other models.
Semiconductor like behavior - cutting edge vs two generations ago
In the short run, LLMs are likely to be similar to the microprocessor industry in the 90s and 2000s. During that era, Intel had a clear advantage technologically and was always 2-3 years ahead of its competitors such as AMD. This means having an Intel chip created a clear advantage to PC performance.
Each Intel CPU design & fab (on roughly an 18-month iteration timeframes - sound familiar?) cost quite a bit more to build than the prior generation. This, alongside clever sales and marketing deals, enforced a moat behind Intel in its market. This moat lasted from the 1980s until recently.

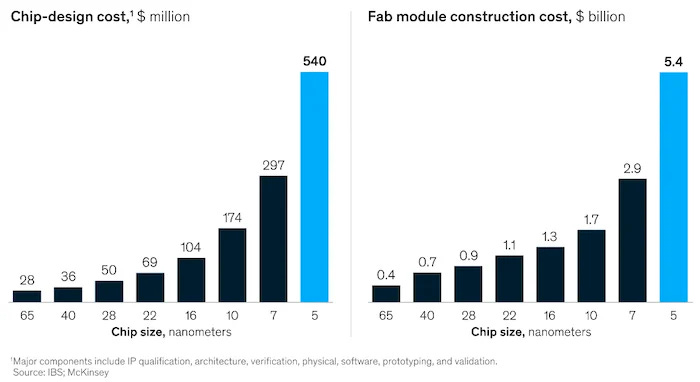
Everyone coveted the latest Intel CPUs that were always more performant than the prior generation. This meant that the most cutting edge applications needed the latest microprocessor. However, the older chips found many applications at 1/10th or 1/100th the price.
Similarly, the last generation or two of LLMs may be dirt cheap to train (see e.g. GPT-2 if started from scratch today). Prior generations of models may default to open source or fragmentation. We may end up with a world where GPT N (or equivalent) is at the cutting edge with clear differentiation for key applications, while GPT N-1 or N-2 is cheap and broadly accessible for applications with lower fidelity needs or “good enough” models.
If you assume the foundation model training costs continue to ramp with each subsequent model, then the next 2-3 years is probably the last chance for a startup to enter this market without a deep-pocketed “strategic” backer such as Microsoft, Google, Facebook, Apple or Amazon.
A startup will need escape velocity from a revenue and technological progress perspective to win after that. However, there may also be interesting tech breakthroughs that could impact this - e.g. if the startup invents AGI or a program that can bootstrap by writing its own code and training faster than humans can.
Cloud timing as example
Despite having the infrastructure to build a cloud platform, it took Google 2 years for its first GCP service and a few more years after that for GCP to be a more complete solution. Similarly Azure launched 4 years after the first part of AWS launched. It usually takes a few years for a large company to respond and act on a threat. LLMs may be a similar thing that Google and AWS will need to respond to in order to be competitive as cloud platform providers.

Proxy war - Alibaba / Tencent model.
Sometimes companies may compete via arms length proxies. For example, Alibaba and Tencent in China often fund / buy deep ownership in, and then distribute, competitive products. Similarly, IBM used to fund Linux to counteract Microsoft, and Google, Apple, and Mozilla all back different branches of webkit as a sort of browser proxy war. For AI, the reason to have an arms length relationship may include PR and safety reasons, the ability for an indirect subsidiary or proxy to have more nimbleness and freedom, financial incentivization, or other reasons.
One potential future world would be OpenAI/MSFT versus Anthropic/Google versus Stability/Amazon vs Cohere/Meta (these are all made up pairings!!!!!). In other words, each incumbent would chose a startup partner to take on the brand and safety risk while buying major ownership in said startup. In exchange, the startup would get access to data, distribution, and other resources from the incumbent. To some extent, this results in roughly the same market structure as (2).
3. Niche models matter, or a major backer of open source shows up.
Another version of the world is one in which niche models end up performing roughly as well as, or better then, the large scale models for most applications (or at least the most important ones). In this world, a highly targeted robust data set would work as well as a large foundation model, meaning the barrier of entry would cost hundreds of thousands to millions in compute and data labeling/cleaning dramatically lowering the bar for market entry. Early data points suggest that LLMs augmented by niche data sets (see e.g. Codex and Github copilot) tend to outperform niche models, but a few generations from now that may or may not hold. This is an unlikely world in the next 1-2 years, but may become very important in the future. In this case the world of AI fragments and the big models decrease in importance for some areas.
Relatedly, a massive funder of open source shows up to create the “open model alternative”. Maybe the gulf countries create the “oil to AI fund”, or a deep pocketed company views open source foundation models as important to its market structure (similar to IBM being the main backer of Linux in the 90s to offset Microsoft and others). If there ends up being enough capital to fund open source alternatives, it would lead to a more fragmented market and world.
4. Brand, distribution, product matters. Another view of the world is that models will commoditize rapidly, but brand, distribution, and product will matter as much or more. For example Bing is roughly equivalent to Google on many measures but Google has maintained its market position via buying paid distribution + branding. In one future version of the world we will end up with 2-3 core API platforms provided by larger companies (e.g. OpenAI + MSFT, Google, and maybe others - e.g. Amazon or Facebook + Anthropic), and then a federated set of open source or bespoke models to cover numerous use cases.
B2: Open source (OS) vs closed:
Big funding sources or consistently 1-2 generations (1-3 years) behind?
Most successful open source projects (webkit, linux, etc) have eventually had large corporate backers for their funding and development. For example, Linux was heavily funded by IBM in the 1990s to counterbalance Microsoft for server side software. Crypto (BTC and ETH) are the obvious OS counterexamples to this, although one could argue given monetization being built directly into the crypto protocol equated in these groups self-funding. In some sense, crypto is its own corporate sponsor.
Potential backers of OS LLMs may include governments (for example Bloom was in part funded by France), sovereign wealth (the Gulf “Oil for AI” trade), large corporations without a horse in the race but who may benefit from more LLM use (NVIDIA? Amazon?), or a major philanthropic effort.
As discussed above, scale of compute really matters for cutting edge LLM models. This suggests in the medium term, unless a large-scale backer of OS LLMs emerges, OS LLMs may end up a generation or two behind (1-2 years?) closed source models due to the sheer cost of training.
Models that are 1 generation behind will be incredibly useful for all sorts of developers and applications, but the most cutting edge highest fidelity models for the most advanced uses may stay closed source. For example, when GPT-7 exists, if it costs $500M to train than maybe the OS foundation models will be at GPT-6 or 5 equivalents. Depending on where that is on the S-curve, it may or may not matter for many applications and OS may be a great alternative for some applications.

The shift from OS to proprietary models may also be reflected in the switch in terms of proportion of research coming from academia versus industry in AI/ML. Many industrial labs are increasingly saying they will stop publishing as many results as the competition in the market heats up, decreasing access of OSS and academia to progress in the field.

In the long run, the performance S-curve is likely to saturate (barring true AGI lift off) meaning if not funded by major backers OSS will still catch up and might eventually surpass closed source.
B3: Bottlenecks and approaches to scale?
A world in which capital acts as a moat is also one in which sheer scale (of compute, data, and other factors) matters. A money based moat only exists in a world where we can keep scaling inputs faster than cost in the industry rises. Image generation is a good counter example where today scale of dollars and GPUs is not preventing new entrants or innovation. For LLMs, the factors that may impact both cost and scaling of models over time:
Data availability and scale. At some point the web will be exhausted as a data source. Video (YouTube, Vimeo, TikTok, etc.), voice (call center logs), code repositories, all books published, and other data sources at some point may be exhausted or be proprietary in nature. One can imagine a future world where people are paid to record their lives and passively capture it into models. Synthetic data will be increasingly important over time, and is already a key component of self-driving car autonomy and other ML-driven fields. It is likely to grow in importance for LLMs.
Human feedback and training. RLHF (reinforcement learning from human feedback) is a core component to reducing the need for prompt engineering + training models on specific human-derived tasks. Scaling this may eventually become quite capital intensive for specific areas, as well eventually morph from human based feedback to machine based.
Fine tuning and training. Small models may out-perform large models when properly fine tuned.
Semiconductor layer. There is still an enormous amount of optimization to be done at the chip level - with early TPUs as a striking example of how much the industry could benefit from incremental custom ASICs. In parallel, GPU or TPU hacking to squeeze extra performance out of existing hardware still has some room to go.
System optimization. There is a lot of room to optimize the systems and infrastructure side of LLMs. Similarly, differential weighing of tokens by complexity or information content are being explored.
Inference versus training. Often when a human is presented with a problem, she will pause for a few seconds or a few minutes to think before acting. Similarly, while enormous emphasis is put on training, more approaches (and compute) applied at the time of inference could help
New architectures. New breakthrough architectures could create a new leap in AI, just as transformers had to prior convolutional models. There may be some approaches to AI whose value only becomes evident at scale, that are too expensive to explore today.
Other algorithmic / models on top of the transformers. The brain has specialized modules for specific functions. Incremental or specialized types of models may optimize overall LLM systems and outputs.
Overall, while there are a lot of reasonably orthogonal ways to scale things up that are not purely capital based. However, in the medium term it seems that even if you implement many of these things, scale will still create an advantage for LLMs.
B4: When does scale-based value asymptote?
Many technologies eventually reach an asymptote, often on an S-curve (sigmoid function). Sometimes this curve has underlying physical drivers - for example the line width of a transistor on a chip eventually runs into an atomic limit - and this in turn eventually limits what can be done with certain semiconductor technologies. An open question is the time horizon over which scaling compute saturates existing data sets and AI architectures. If AI scaling hits the top of the S curve quickly, the market will fragment rapidly into more players and open source usage (as costs will drop over time while model performance will not appreciate much). In contrast, if there is a long time horizon to reach an asymptote, the industry structure is likely to stay more static and limited per the potential outcomes above.

B5: Does value aggregate to platforms or apps?
In some worlds, much of the application value aggregates to the platform as it forward integrates into the handful of apps that do best on it. For example, Microsoft famously bought or killed all the competitors to MS Office. In contrast, AWS, Azure, and GCP are all massive businesses - and yet roughly all SaaS, enterprise, and consumer companies benefit from these platforms and have aggregated their own value without the platforms forward integrating into them. In general, the very highest quality highest scale businesses in tech right now (Apple, Amazon, Google, Microsoft) own the platforms for devices (iOS, webkit, MS OS, Android) and cloud (Azure, AWS, GCP). However, lots of other platform or API business (Stripe, Adyen, Twilio, etc.), data infra (Snowflake, Databricks, dbt) and applications (Meta, Salesforce etc) have all thrived in this world.
The most likely answer on platforms versus apps is “both”. Some platforms will forward integrate into obvious applications (ChatGpt?) while most applications will be stand-alone and be able to create enormous value of their own. Yet other applications will use bespoke niche models and proprietary data to differentiate. I have discussed a related question of startup versus incumbent value capture from AI elsewhere.
All of the above could be wrong
Things are changing incredibly fast in the AI world. A technological or performance breakthrough could upend everything written above. We also still do not know how all the big tech companies will react. As such, the only real certainty is we are living through an exciting moment in time and a technology discontinuity. Exciting times!

Thanks to Ben Thompson and Nat Friedman for comments on this post.
Notes
[1] There is some nuance on this, as cloud providers have an incentive to provide compute resources in exchange for equity, and they then recognize the compute utilization as revenue. This means funding LLM companies may increase their own revenue and market cap and lead to a short to medium term incentive to keep doing “strategic” deals with foundation companies.
MY BOOK
You can order the High Growth Handbook here. Or read it online for free.
OTHER POSTS
Firesides & Podcasts
Markets:
Startup life
Co-Founders
Raising Money
Old Crypto Stuff: